Preamble
This is the start of a series of posts about managing AL development with Git. I don’t profess to be a Git expert and much of what I write about will not exclusively apply to Business Central development. This is a collection of approaches I’ve found to be useful when it comes to managing our source code. Take what you will, discard the rest, vociferously argue with me if you feel strongly enough about it.
Preamble over. Let’s get on with it.
(Re)Writing History
My introduction to source control was using TFVC (more here). As a centralised source control system when you check code in it is immediately pushed to the server. All the changes that anyone pushes make a nice, neat, straight line. Check-ins are given a changeset number. Those numbers are unique, always increase and can never be changed. History has been written.
Stands to reason. We can’t go back and change the past. But what if we could…?
You can use Git like this if you want. Make a change, commit the change, make a change, commit the change. Keep committing in a straight line and keep your history really simple.
* cd03362 (HEAD -> master) Add missing caption for new field * 94388de Populate new Customer field OnInsert * c49b9c9 Add new field to Customer card
Unlike TFVC you have to push those commits to the server before anyone can see them. Do that on a regular basis and make sure your colleagues are pulling your changes before they commit theirs and not much can go wrong.
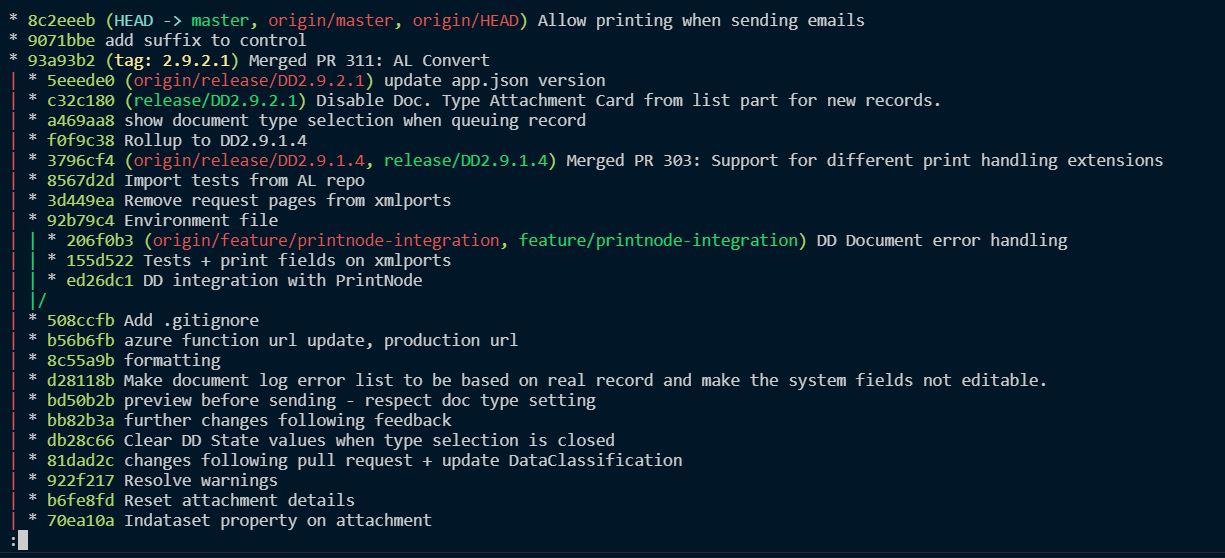
That’s fine as far as it goes, but it’s not particularly elegant. What about when you make another commit correcting a typo in the caption? (Reading the history from bottom to top)
* 1ee22a6 (HEAD -> master) Correct typo in caption * cd03362 Add missing caption for new field * 94388de Populate new Customer field OnInsert * c49b9c9 Add new field to Customer card
Now we’ve got two commits in the history of the project just to add a caption and get the caption correct. With TFVC you’re stuck with it, but with Git, we’ve got complete control over the history of the project.
Tell a Story
Having control over the history of the project ought to make us think differently about it. What is the history for anyway? It’s to help other developers, including our future selves, understand what changes have been made to the code and why they have been made. The best way I’ve heard this described is that we can use the commits to tell the story of the changes that we’ve made.
When you were working on this feature what changes did you make? What code did you add or remove?
The reality might be something like:
- Added a field to the customer table
- Added an OnInsert trigger to populate the new field
- Added a missing caption
- Corrected a typo in the caption
- Added the field to the customer card
- Realised the field was in the wrong group, moved it
- Added a missing application area
- Realised I should have included a suffix to the field name, renamed the field
Development can be messy. We make mistakes and fix them as we go. But is that history easy to read? Do other developers care about all the steps in the process? Does future you need to reminded of all those mistakes? No. We can do better than that.
Terminal
From here on in we’re going to use a terminal – command prompt / bash / PowerShell to manipulate the history of the repository. Don’t be intimidated – it’s fine with a little practice. I’d recommend a combination of PowerShell and posh-git module – its tab completion and status in the prompt makes life easier.
Incidentally, to show the graphs of the history in this post I’ve used:
git log --graph --oneline --all
i.e. show the log (history) of the branch as a graph with each commit on a single line.
git commit –amend
The first tool we’ve got to put some of this mess right is the –amend switch to the commit command. Perfect for when you realise you’d made a mistake with the latest commit. You’ve found a typo or forgotten to include some changes that should have been made with it.
Stage the changes that you want to include with the previous commit (using git add or VS Code or some other UI tool). Rather than committing them in the UI switch to a terminal and type git commit –amend

Git will open a text file with the commit comment at the top and details of the changes which are included in the commit underneath. Change the commit comment if you want and close the file. You’ll have selected the text editor you want to use when installing Git. If you can’t remember doing that then you’ll find out what you chose now. You can change the editor in Git’s config if you like.
Congratulations. You just rewrote the history of the repo. You can do that perfectly safely on commits that are only in your local copy of the repository.
Only Share Your Changes When You’re Ready
This is one of the big benefits of a distributed source control system like Git. It’s your copy of the repo. You can do whatever you like to it without affecting anyone else until you are ready. Make mistakes. Muck about with different ideas. Start again. Redesign. Whatever.
When you are happy with the changes that you’ve made and the story that the commits tell – push those changes to the server and let your colleagues get their hands on them.
Different Versions of History
Before going on to describe other methods for manipulating history it is probably responsible to briefly discuss the consequences of rewriting commits that have been already been pushed to the server.
If this is a commit that has already been pushed to the server you should know that your history no longer matches the history on the remote.
The graph will end up looking something like this. My local copy of the commit has a different commit hash (c1152b2) to the remote copy (aea8ffa) – usually, but not necessary, called “origin”. Notice the posh-git prompt indicates this with the up and down arrows. 1 commit ahead of master, 1 commit behind master.
* c1152b2 (HEAD -> master) Correct typo in caption | * aea8ffa (origin/master) Correct typo in caption |/ * cd03362 Add missing caption for new field * 94388de Populate new Customer field OnInsert * c49b9c9 Add new field to Customer card C:\Users\james.pearson.TECMAN\Desktop\GitDemo [master ↓1 ↑1]>
While this is the case I won’t be able to push my changes to the remote. This is what happens when I run git push
! [rejected] master -> master (non-fast-forward) error: failed to push some refs to 'C:\users\james.pearson.TECMAN\Desktop\GitDemo-Origin.git' hint: Updates were rejected because the tip of your current branch is behind hint: its remote counterpart. Integrate the remote changes (e.g. hint: 'git pull …') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Updates were rejected. There is a danger that some commits on the server will be lost if my copy of the master branch is pulled as is.
The advice is to pull the commits that are on the server and incorporate them into my local copy before I push my changes again. Usually good advice. Only, in this case I want that change to be lost. The commit that is in the server’s copy but not mine is the commit that I want to overwrite. In which case, I can safely force my changes onto the server with git push -f
Before forcing your changes make sure that you know which changes are going to be lost i.e. everything from the point at which the graph diverges.
If that all sounds a little daunting, don’t do it. Practice amending local commits first and getting them into shape before you push them to the server. Being able to confidently manipulate the history of the repo with a few key commands will prove an invaluable tool in your own work and especially as you collaborate on the same code with others.
Next up, interactive rebasing.