

Extension Settings
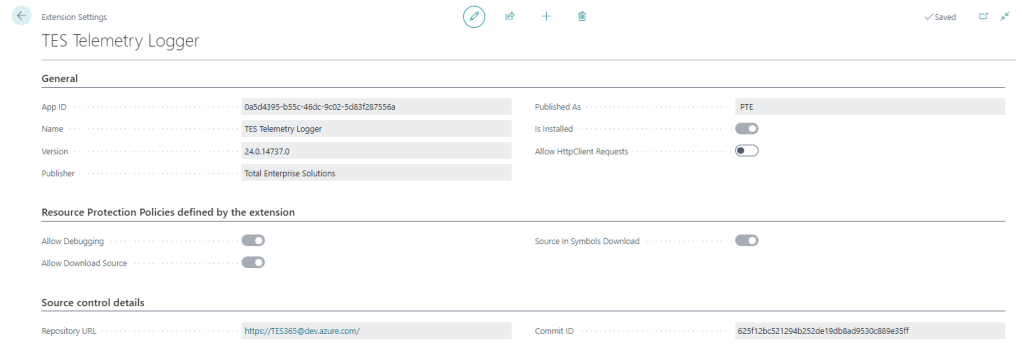
For a long time the only thing additional data you could see on the Extension Settings page was whether to allow Http calls from this extension (the Allow HttpClient Requests checkbox). This page has got some love in BC25.
That setting is still the only thing that you can control, but now you can also see:
Resource Protection Policies
Corresponding to resource exposure policies in app.json (maybe “exposure” sounded a little risqué for the user interface). This indicates whether you can debug, download the source code and whether the source is included when you download the symbols.

That might be useful to know before you create a project to download the symbols and attempt to debug something.
Interestingly, extensions which don’t expose their source code get the red No of shame in the Extension Management list.
Source Control Details
Includes the URL of the repository and the commit hash that the extension was created from. That’s cool – you can link straight from the Extension Settings page to the repo in DevOps / GitHub / wherever your source is. That’s a nice feature either for your own extensions or open source extensions that you are using.
It may be that each time you build an app that you already give it an unambiguous, unique version number (we include the DevOps unique build id in the extension version) but the commit hash is nice to see as well.
How Does it Know?
Where does that information come from? It is included in the NaxManifest file, extract the .app file with 7-Zip and take a look.
<ResourceExposurePolicy AllowDebugging="true" AllowDownloadingSource="true" IncludeSourceInSymbolFile="true" ApplyToDevExtension="false"/>
<KeyVaultUrls/>
<Source RepositoryUrl="https://TES365@dev.azure.com/..." Commit="625f12bc521294b252de19db8ad9530c889e35ff"/>
<Build Timestamp="2024-09-10T12:49:40.2694758Z" CompilerVersion="13.1.16.16524"/>
<AlternateIds/>How Does That Info Get Populated?
When the app is compiled by alc.exe there are additional switches to set this information. These are some of the switches that you can set when compiling the app.

These switches are not set when you compile the app in VS Code (crack the app file open with 7-Zip and check), but you can set them during the compilation step of your build. If you are using DevOps pipelines you can make use of these built-in variables Build.SourceVersion and Build.Repository.Uri to get the correct values.
&'$(alcPath)' /project:"$(projectPath)" /sourcecommit:"$(Build.SourceVersion)" /sourcerepositoryurl:"$(Build.Repository.Uri)" ... (truncated)That’s if you roll your own build pipelines. If you use some other tooling (AL-Go for GitHub, ALOps etc.) then the compilation step will be in their code. They may have already implemented this, I don’t know.
Side note: Microsoft want to push us to use 3rd party tooling rather than making our own (e.g. I watched this podcast with Freddy the other day) but personally I still see enough value in having control over the whole DevOps process to justify the small amount of time I spend maintaining and improving it. I’m open to changing that stance one day, but not today.








