This is part two of a series about using Git to manage your Business Central development. This time – rebasing. It seems that rebasing can be something of a daunting subject. It needn’t be. Let’s start with identifying the base of a branch before worrying about rebasing.
Example Repo
Imagine this repository where I’ve created a new branch feature/new-field-on-sales-docs to do some development.
* 445e3e1 (HEAD -> feature/new-field-on-sales-docs) Add field to Order Confirmation
* fddf9fb Set DataClassification
* 176af2d Set field on customer validation
* 3cd4889 Add field to Sales Header
* 3894d1a (origin/master, master) Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
We can consider that the base of the feature branch is where it diverges from the master branch. In this example commit 3894d1a is the base (“Correct typo in caption”). Simple. Now a more complex example:
* 412ce8f (HEAD -> bug/some-bug-fix) Fixing a bug in the bug fix
* 7df90bf Fixing a bug
| * d88a322 (feature/another-feature) And some more development
| * 0d16a39 More development
|/
| * 445e3e1 (feature/new-field-on-sales-docs) Add field to Order Confirmation
| * fddf9fb Set DataClassification
| * 176af2d Set field on customer validation
| * 3cd4889 Add field to Sales Header
|/
* 3894d1a (origin/master, master) Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
I’ve got three branches on the go for a couple of new features and a bug fix. Follow the lines on the graph (created with git log –oneline –all –graph) and notice that they all diverge from master at the same commit as before. That is the base of each of the branches.
Now imagine that the bug fix is merged into the master branch – it was some urgent fix that we needed to push out to customers. I’ve merged the bug fix branch, deleted it and pushed the master branch to the server.
git checkout master
git merge bug/some-bug-fix
git push
git branch bug/some-bug-fix -d
The graph now looks like this:
* 412ce8f (HEAD -> master, origin/master) Fixing a bug in the bug fix
* 7df90bf Fixing a bug
| * d88a322 (feature/another-feature) And some more development
| * 0d16a39 More development
|/
| * 445e3e1 (feature/new-field-on-sales-docs) Add field to Order Confirmation
| * fddf9fb Set DataClassification
| * 176af2d Set field on customer validation
| * 3cd4889 Add field to Sales Header
|/
* 3894d1a Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
Merge Commit vs Rebase Example
Now for an example of what rebasing is and why you might want to use it.
Despite what was happened to the master branch notice that the feature branches still diverge from the master branch at the same commit. They still have the same base. This is one reason you might want to consider rebasing. If I was to merge the feature/another-feature branch into master now I would create a merge commit. Like this:
* 44c19a0 (HEAD -> master) Merge branch 'feature/another-feature'
|\
| * d88a322 (feature/another-feature) And some more development
| * 0d16a39 More development
* | 412ce8f (origin/master) Fixing a bug in the bug fix
* | 7df90bf Fixing a bug
|/
| * 445e3e1 (feature/new-field-on-sales-docs) Add field to Order Confirmation
| * fddf9fb Set DataClassification
| * 176af2d Set field on customer validation
| * 3cd4889 Add field to Sales Header
|/
* 3894d1a Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
The graph illustrates that the master branch and the feature branch diverged before being merged back together. An alternative solution would be to rebase the feature branch onto the master branch. What does that mean?
Git will identify the point at which the feature branch and the target branch (master in this case) diverged. This is commit 3894d1a as noted above. It will then rewind the changes that have been made since that point and replay them on top of the target branch.
git checkout feature/another-feature
git rebase master
First, rewinding head to replay your work on top of it…
Applying: More development
Applying: And some more development
And now the graph shows this
* ac25a75 (HEAD -> feature/another-feature) And some more development
* 8db81ff More development
* 412ce8f (origin/master, master) Fixing a bug in the bug fix
* 7df90bf Fixing a bug
| * 445e3e1 (feature/new-field-on-sales-docs) Add field to Order Confirmation
| * fddf9fb Set DataClassification
| * 176af2d Set field on customer validation
| * 3cd4889 Add field to Sales Header
|/
* 3894d1a Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
The two commits that comprised the feature branch have been moved to sit on top of the master branch. It’s as if the development on the feature had been started after the bug fix changes had been made.
Notice that the commit ids are different – due to how Git works internally – but the effect is the same in both cases. The version of the code at the top of the log contains the changes for the both the bug fix and the new feature.
I won’t discuss the pros and cons of either approach. Rebasing keeps the history neater – all the commits line up in a straight line. Merge commits reflect what actually happened and the order in which changes were made. There are plenty of proponents of both approaches if you want to follow the subject up elsewhere.
Interactive Rebasing
In the previous post I was discussing the value of amending commits so that they tell the story of your development. With git amend we can edit the contents and/or commit message of the previous commit.
Remember that rebasing identifies a series of commits and replays them onto another commit. That’s useful for moving commits around. It is also very useful in helping to create the story of your development. Let me simplify the example again to show you what I mean.
* 445e3e1 (feature/new-field-on-sales-docs) Add field to Order Confirmation
* fddf9fb Set DataClassification
* 176af2d Set field on customer validation
* 3cd4889 Add field to Sales Header
* 3894d1a (HEAD -> master, origin/master) Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
Look at commit fddf9fb Set DataClassification. I added a new field to the Sales Header table but forgot to set the DataClassification property so I’ve gone back and added it separately. That kinda sucks. Other developers don’t need to know that. It’s an unnecessary commit that will only make the history harder to read when we come back to it in the future.
But there’s a problem. I can’t amend the commit because I’ve committed another change since then. Enter interactive rebasing.
git checkout feature/new-field-on-sales-docs
git rebase master -i
This tells Git to identify the commits from the point at which the feature diverges from master, rewind them and then apply them on top of master again. In itself, the command will have no effect as we’re replaying the changes on top of the branch they are already on.
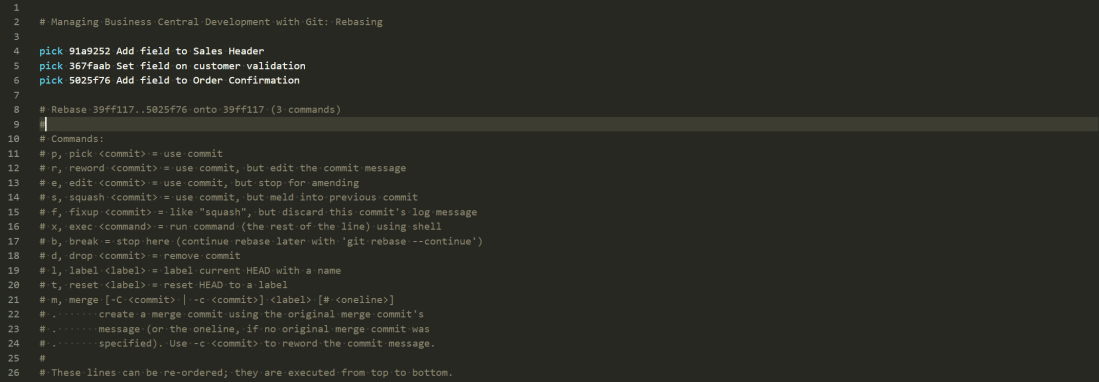
Adding the -i switch runs the command in interactive mode. You’ll see something like this in your text editor.
pick 3cd4889 Add field to Sales Header
pick 176af2d Set field on customer validation
pick fddf9fb Set DataClassification
pick 445e3e1 Add field to Order Confirmation
# Rebase 3894d1a..445e3e1 onto 445e3e1 (4 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup <commit> = like "squash", but discard this commit's log message
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# . create a merge commit using the original merge commit's
# . message (or the oneline, if no original merge commit was
# . specified). Use -c <commit> to reword the commit message.
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
You can think of this as a script that Git will follow to apply the changes on top of the target branch. Read it from top to bottom (unlike the Git log which is read bottom to top).
The script contains the four commits that exist in the feature branch but not in the master branch. By default each of those commits will be “picked” to play onto the target branch.
You can read the command help and see that you can manipulate this script. Reorder the lines to play the commits in a different order. Remove lines altogether to remove the commit. “Squash” one or more commits into a previous line. This is what we want.
I want to squash the “Add field to Sales Header” and “Set DataClassification” commits together. In future it will look as if I’ve made both changes at the same time. Great for hiding my ineptitude from my colleagues but also for making the history more readable. I’ll change the script to this:
pick 3cd4889 Add field to Sales Header
fixup fddf9fb Set DataClassification
pick 176af2d Set field on customer validation
pick 445e3e1 Add field to Order Confirmation
and close the text editor. Git does the rest and now my graph looks like this:
* 5025f76 (HEAD -> feature/new-field-on-sales-docs) Add field to Order Confirmation
* 367faab Set field on customer validation
* 91a9252 Add field to Sales Header
* 3894d1a (origin/master, master) Correct typo in caption
* cd03362 Add missing caption for new field
* 94388de Populate new Customer field OnInsert
* c49b9c9 Add new field to Customer card
Panic Button
Rebasing takes a little practice to get used to. You might want to include the -i switch every time you rebase to start with to check which commits you are moving around.
It isn’t uncommon to run into some merge commits when playing a commit in a rebase. You’ll get something like this alarming looking message
First, rewinding head to replay your work on top of it…
Applying: Add field to Sales Header
Applying: Set field on customer validation
Applying: Add field to Order Confirmation
Using index info to reconstruct a base tree…
Falling back to patching base and 3-way merge…
CONFLICT (add/add): Merge conflict in 173626564
Auto-merging 173626564
error: Failed to merge in the changes.
hint: Use 'git am --show-current-patch' to see the failed patch
Patch failed at 0003 Add field to Order Confirmation
Resolve all conflicts manually, mark them as resolved with
"git add/rm ", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
I’m not a fan of anything that has the word CONFLICT in caps…
VS Code does a nice job of presenting the content of the target branch the “current change” and the changes that are being played as part of the rebase the “incoming change”. Resolve the conflict i.e. edit the conflicted file to correctly merge the current and incoming changes and stage the file.
Once you’ve done that you can continue the rebase with git rebase –continue
If all hell breaks loose and you need to smash the emergency glass you can always run git rebase –abort, breath into a brown paper bag and the repo will be returned to the state it was in before the rebase.